আমরা যখন কম্পিউটার বা মোবাইল ফোনে একটি ব্রাউজার থেকে একটি ওয়েব পেইজ দেখি তখন জিনিসগুলি আসলে কীভাবে কাজ করে। এবং কিভাবে ওয়েব এত সহজ এবং এত সুন্দরভাবে একটা জিনিস আমাদের সামনে তুলে ধরে?
ক্লায়েন্ট এবং সার্ভারঃ
আমরা ক্লায়েন্ট যারা ডিভাইসের (কম্পিউটার বা মোবাইল ফোন ..) মাধ্যমে সার্ভারের সাথে সংযুক্ত থাকি।
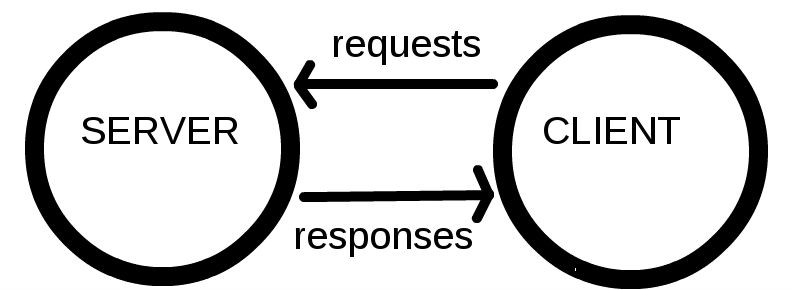
- আরেকটু ভালভাবে বলতে গেলে, ক্লায়েন্ট হচ্ছে যেসব ডিভাইস ইন্টারনেটের সাথে যুক্ত থাকে (যেমনঃ Wi-Fi এর সাথে কানেক্টেড কম্পিউটার, মোবাইল নেটওয়ার্কের সাথে যুক্ত থাকা মোবাইল ফোন) এবং সেসব ডিভাইস যেসব সফটওয়্যারের মাধ্যমে ইন্টারনেটে এক্সেস করে (যেমনঃ ইন্টারনেট ব্রাউজার – Firefox/Chrome )
- সার্ভার হচ্ছে একধরনের কম্পিউটার যে ওয়েব পেইজ, ওয়েবসাইট অথবা ওয়েব অ্যাপ্লিকেশনগুলো জমা থাকে। যখন কোন ক্লায়েন্টের ডিভাইস ওয়েব পেইজে এক্সেস নিতে যায় তখন সার্ভার থেকে সেই ওয়েব পেইজের একটা কপি Client এর ডিভাইসে ডাউনলোড হয়ে যায়, যেতা পরে ক্লায়েন্ট দেখতে পায়।
টুলবক্সের অন্যান্য অংশঃ
এত দিন ধরে ক্লায়েন্ট এবং সার্ভার সম্পর্কে যা জানা গেছে তা আসলে তাদের সম্পূর্ণ চেহারা নয়। পুরো প্রক্রিয়ায় আরও কয়েকটি বিষয় জড়িত।
এতক্ষণ ক্লায়েন্ট এবং সার্ভার নিয়ে যা জানা হলো সেটা অাসলে তাদের পুরো চেহারা না। পুরো প্রসেসটা তাদের সাথে আরো কিছু জিনিস যুক্ত থাকে।

আপাতত, ওয়েব জিনিসটাকে একটা রাস্তা হিসেবে নেওয়া যাক। রাস্তার একেবারে শেষ প্রান্তে, বিচ্ছিন্ন প্রেমিক (ক্লায়েন্ট) দিবাস্বপ্নে তার ঘরে ভিবর। আর রাস্তার ওপাশে প্রেমিকা (সার্ভার) বসে রসগোল্লা খাচ্ছে।
ক্লায়েন্ট এবং সার্ভারের মধ্যে সহজ সম্পর্ক সম্পূর্ণরূপে বোঝার আগে এখানে কিছু জিনিস জানা দরকার:
• ইন্টারনেট সংযোগঃ ক্লায়েন্ট এবং সার্ভারের মধ্যে ডেটা লেনদেনের সুবিধার্থে একটি মাধ্যম থাকতে হবে।
• TCP/IP: Transmission Control Protocol এবং Internet Protocol । এগুলি হল যোগাযোগের প্রোটোকল যা ওয়েব নামক সমুদ্র পার হয়ে সার্ভার থেকে ক্লায়েন্টের কাছে কীভাবে ডেটা পেতে হয় তা বলে।
• DNS: ডোমেইন নেম সার্ভার হল একটি বাস স্ট্যান্ডের মত (ওয়েব ঠিকানার সংগ্রহ) যেখানে সব জায়গায় বাস আছে। ব্রাউজারে যখন কোনো সাইটের ঠিকানা দেওয়া হয়, তখন DNS সেই সাইটের আসল ঠিকানা খুঁজে পায়। কারণ ব্রাউজার জানতে হবে ঠিক কোন হোমে (সার্ভার) কাঙ্খিত ওয়েবসাইট পাওয়া যাবে।
•HTTP ঃ সাত সমুদ্র, তেরো নদী পেরিয়ে অবশেষে ওয়েবসাইটটির বাড়িতে এলাম। এবার আমি টাকা-গাছ চাইব, জানতে চাইলে বলতে হবে, তাকে কীভাবে বাংলা বোঝাব বুঝতে পারছি না। হাইপারটেক্সট ট্রান্সফার প্রোটোকল হল DragoMan (দোভাষী) যা ক্লায়েন্টকে সার্ভারের সাথে যোগাযোগ করতে দেয়।
• কম্পোনেন্ট ফাইল ঃ একটি সাইটের প্রচুর ডাটা ফাইল আকারে সাজানো থাকে। দুটি প্রধান ধরনের ফাইল আছে:
• কোড ফাইল: সাধারণত HTML, CSS, এবং JavaScript-এ কোড থাকে। আরো অনেক ধরনের কোড থাকতে পারে।
# অ্যাসেটসঃ কোড ছাড়াও আরও অনেক ধরনের ফাইল আছে যেমন ইমেজ, অডিও, ভিডিও, টেক্সট এবং পিডিএফ।
তাই ক্লায়েন্ট এবং সার্ভারের মধ্যে কি ঘটেছে?
যখন একটি সাইটের ঠিকানা ব্রাউজারে টাইপ করা হয়:
1. ব্রাউজারটি DNS সার্ভারে যায় এবং সাইটের আসল ঠিকানা খুঁজে পায়।
2. ব্রাউজারটি মূল ঠিকানা সহ HTTP এর মাধ্যমে সাইটের একটি অনুলিপি পাওয়ার অনুরোধ করে৷ এর মধ্যে কিছু লেনদেন ইন্টারনেট সংযোগের মাধ্যমে এবং TCP/IP এর নিয়ম অনুযায়ী করা হয়।
3. সার্ভার ক্লায়েন্টের অনুরোধ গ্রহণ করে এবং একটি “200 ওকে” টাইপ সংকেত পাঠায় যার অর্থ “হ্যাঁ, আপনি সাইটটি দেখতে পারেন” এবং তারপর প্যাকেট আকারে ক্লায়েন্টের কাছে ডেটা পাঠায়।
4. ক্লায়েন্টের ব্রাউজার সেই ডেটা প্যাকেটগুলিকে পুনরায় সাজায় এবং পুরো সাইটটি প্রদর্শন করে।
DNS কি?
ওয়েবসাইটের আসল ঠিকানা দেখা মোটেও সুবিধাজনক নয়, এবং মনে রাখা খুবই কঠিন। সাইটের ঠিকানা অনেকটা 173.194.121.32 এর মত যাকে IP ঠিকানা বলা হয়। এই আইপি ঠিকানাটি একমাত্র ওয়েব ঠিকানা যা অনন্য। আর আইপি নামক এই সমস্যা থেকে মানুষকে বাঁচাতেই ডিএনএসের আবির্ভাব। DNS হল একটি বিশেষ সার্ভার যা ওয়েবসাইটের নাম তার ঠিকানায় নিয়ে যায়। এবং হ্যাঁ, আমরা IP ঠিকানা সহ ওয়েবসাইটের ঠিকানায়ও যেতে পারি, উদাহরণস্বরূপ: 173.194.121.32 ব্রাউজারের ঠিকানা বারে http://www.google.com টাইপ না করে, আমরা সরাসরি এর ওয়েব পেজে যেতে পারি।
Johir Ahemmod Chowduri
Instructor, Computer Technology
Daffodil Polytechnic Institute
Add a Comment
You must be logged in to post a comment